Principal Component Analysis Of TF-IDF In Click-Through Rate Prediction
Paper LinkDelhi Technological University Jan 2016- Jun 2016
We make model to predict the probability whether a user will click on a particular advertisement or not. The dataset used is that of Avito.ru provided as a part of the Kaggle competition- “Avito Contextual Ads Prediction”. Here Principal Component Analysis on the Search and Query features is used, some extra count variables are made for integrate the categorical variables. Lastly logistic regression, SVM and gradient boosting algorithms are applied for classification into click or no-clicks.
Data Collection
We have a training data set of 10.2GB and a test set of 531MB from Avito Context Ad Clicks Kaggle Competition. For model formation we have taken small subsets of these data. The database has 8 tables. trainSearchStream.tsv and testSearchStream.tsv are two main data tables used in this paper of predictive model. They have a column ObjectType which shows which type of advertisement. Avito.ru supports 3 types of advertisements:
- Regular: Free ads which go down with time
- Highlighted: Advertisers pay a fixed amount for these ads. The ad stays on the top for a fixed amount of time then is shifted down.
- Contextual: Advertisers pay per click. Therefore, it is necessary to predict the probability of click, so as to estimate the revenue from the ads.
Experiments
For running our experiments, we split the data into training and test data sets. The split was done based on the active time span for each user. 70% of each user’s tweeting activity is used for the training data while the remaining 30% is retained for testing. For inactive users (1-2 tweet only),we included 80% of such users in the training data, while the remaining users were considered ascold-start users in the test data. This was done to analyze the performance of our algorithm for cold and warm users. In our algorithm we have proposed two major ideas to recommend more personalized and time based recommendations.
- Recommendations based on patterns in monthly interests in topics
- Hybrid Recommendations generated based on user clustering by Louvain community detection and article clustering based on LDA.
Model Evaluation Metrics
The evaluation metric used was the log loss function, as mentioned in the Kaggle competition. It is a classification loss function. Log-loss measures the accuracy of a classifier. It is used when the model outputs a probability for each class, rather than just the most likely class. Log loss measures the uncertainty of the probabilities of your model by comparing them to the true labels.
Result and Conclusion
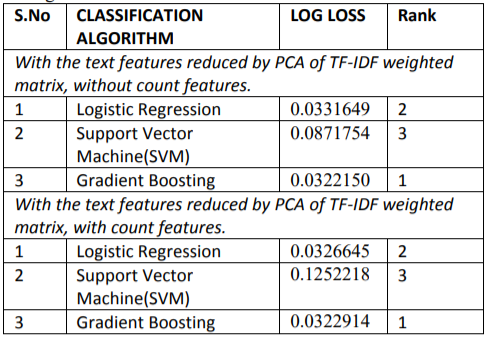
We observed the performance of various classification models:
- With the text features reduced by PCA of TF-IDF weighted matrix, without count features.
- With the text features reduced by PCA of TF-IDF weighted matrix, with count features.