The Insta-Dead:The rhetoric of the human remains trade on Instagram Replication Project
Github LinkUniversity of Washington Jan 2020 - Mar 2020
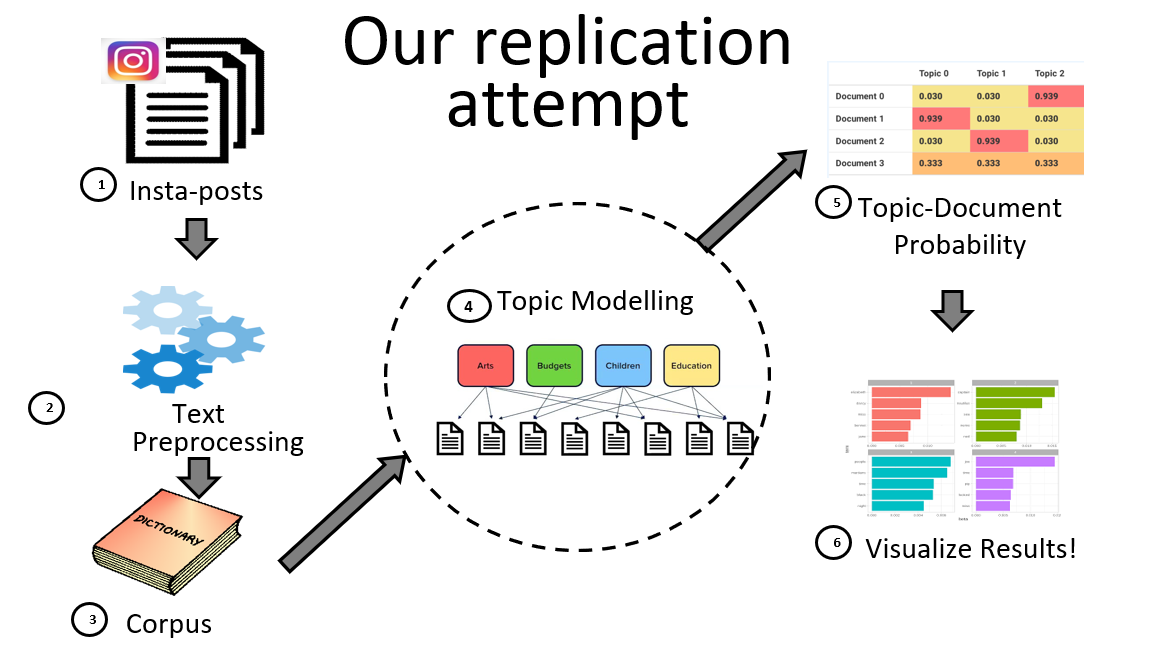
The purpose of this project is to reproduce the figures published in the Insta-Dead paper by Damien Huffer and Shawn Graham. The paper explores the trade of human skulls and bones taking place on the social media platform, Instagram. We would like to use the data provided by the authors to reproduce the results of the paper, ideally using R. The figure we are reproducing involves topic modelling for posts by a single Instagram user/trader. For LDA, by using the gensim library in Python as a replacement for the mallet library we would like to reproduce similar topics and generate similar topic weights for eaach post by the user.
Paper: Huffer, D. and Graham, S. 2017 The Insta-Dead: The rhetoric of the human remains trade on Instagram, Internet Archaeology 45. https://doi.org/10.11141/ia.45.5.
Data Collection
The links to download the dataset have been well documented in the repository provided by the original authors here. The data consists of year, username, text. Here year is the date of posting, username is the ID associated with the particular user and text is the content of the post. Dataset consists of 132,225 instagram posts pertaining to hashtags related to this area of study.
Experiments
We choose to vary the topic modeling algorithm used in this paper. We wanted to explore how topic modeling is carried out in Python using the 'gensim' library. The Gensim library uses another LDA method like mallet, that performs Variational Baye's sampling techniques. This is different from the mallet algorithm that is based on Gibb's sampling. The Gensim algorithm performs faster than mallet due to fewer iterations. However the mallet algorithm is known to give more accurate results. We hope to achieve similar results by using Gensim.Gensim provides very desciptive in-built visualizations in Python. However the results are not easy to compare with the R visualization. Thus, we decided to use the ‘gensim’ package in Python to perform topic modeling and the ggplot library in R to draw the visualization for comparison.
Result and Conclusion
Using the python package ‘gensim’ for performing the topic modeling and R for compiling the data and plotting the figure, we are able to reproduce the experimental data and reproduce the Figure to a large extent. The selected keywords for the 25 topics in our reproduced figure are slightly different than those in the original one, although they share many overlaps, such as oddities, skullart, tattoo and bones. This can be attributed to the differences in the internal workings of the packages in R and python. Based on the comparison of the complete topic names, we find some topics in the replication method that are semantically quite similar to the original topics