Time-Aware News Recommendation Engine Based on Twitter User History
Github LinkUniversity of Washington Mar 2020 - Jun 2020
Proposed a method for news recommendation on social media platforms. Recommendation engine employs user-side information as well as the news article information for a hybrid Collaborative Filtering and Content-Based Filtering (CF-CBF) approach, to recommend a news article to the user. Experimented with both vectorized and graph-based approaches to cluster users based on their news consumption patterns. This forms the basis of the Collaborative Filtering component of the algorithm. On the item-side, experimented with vectorized and probabilistic approaches to find article clusters. Combining this with the time specific user interest for each topic, get a Content-Based Filtering (CBF) recommendation score. Finally, we take the two recommendation scores and combine them to a single score. Recommend the most relevant articles from the topics with the highest CF-CBF score for each user at a particular time period.
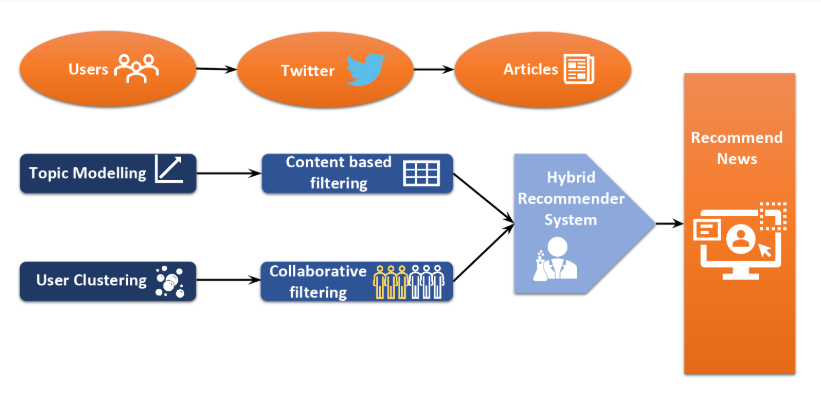
Data Collection
To creat a news recommendation engine, news as well as user data to model the user-item interactions, was needed. While there are many text corpora for news article data, literature surveys showed that there are no openly available data sources to collect user interactions with news-items. Therefore, we decided to use Twitter data. We used tweets/retweets as the links between users and news articles. The twitter data used in our project was collected using the FakeNewsNet data repository. The repository provides a web-scraping tool that collects tweet and retweet data which refer to Politifact news articles. This data is pulled using the Twitter API.
Experiments
For running our experiments, we split the data into training and test data sets. The split was done based on the active time span for each user. 70% of each user’s tweeting activity is used for the training data while the remaining 30% is retained for testing. For inactive users (1-2 tweet only),we included 80% of such users in the training data, while the remaining users were considered ascold-start users in the test data. This was done to analyze the performance of our algorithm for cold and warm users. In our algorithm we have proposed two major ideas to recommend more personalized and time based recommendations.
- Recommendations based on patterns in monthly interests in topics
- Hybrid Recommendations generated based on user clustering by Louvain community detection and article clustering based on LDA.
Model Evaluation Metrics
We compare our algorithm against the baseline models, by comparing metrics like MAP@K, Precision@K, Recall@K, and Area under the Curve (AUC). Our recommender system produces a list of recommendations for each user in the test set. MAP@K gives insight into how relevant the list of recommended items are while giving a ranking to the recommendations as well. Therefore, by using this metric we can determine how well we are front-loading our recommendations. Precision@K and Recall@K do not take into account the ordering of the articles. These metrics simply calculate the precision and recall by considering only the subset of our top recommendations from rank 1 through k. They are informative in indicating how well the system is performing in terms of recommending the relevant articles. The Precision-Recall curve takes into account both precision and recall of the recommendation system. Since there is a tradeoff between precision and recall, the area under the curve (AUC) can therefore be used as a single balanced measure for the overall quality of a recommendation system.
Result and Conclusion
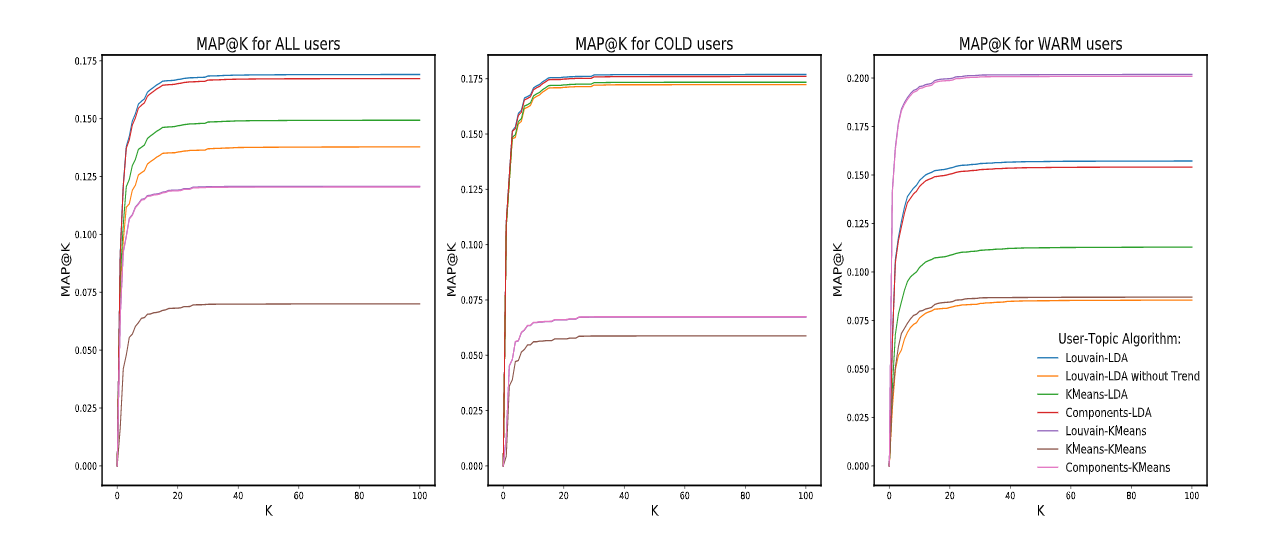
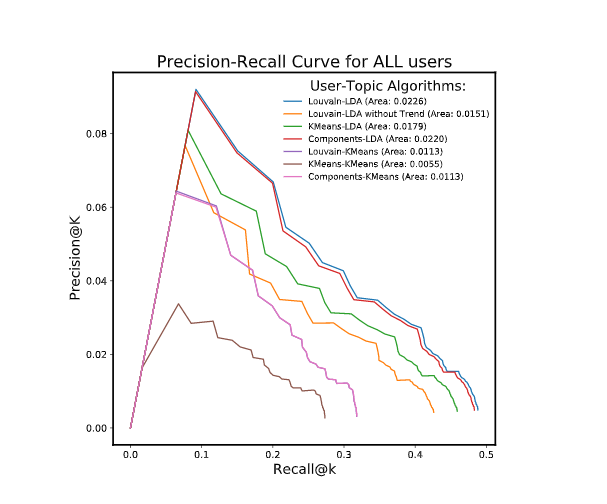
News Recommendation Systems pose a challenging problem due to the high dimensionality of the data. Hybrid recommendations help to reduce the dimensionality, as well as improve recommendations based on similarities between within news articles and within users. The hybrid approach also helps to solve the User-side and Item-side cold start problems. Using the Louvain community detection algorithm, we find that we are able to group the users quite well in comparison to K-Means clustering. We also find that LDA performs quite well as a topic modeling algorithm to classify similar articles. The popularity of different topics vary over time. Utilizing users’ time-based interest in different topics, tends to improve the model by recommending more relevant topics at any given time. The smoothing constant G that we have used in our implementation is an estimate of the average number of articles read across all time periods. The purpose of the smoothing constant is to take into account new users who do not have a substantial reading history. For the future scope of the project, it would be interesting to study how tuning the smoothing constant can improve the performance of the model.